A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 11
Volume 11
Issue 11
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Yin, J. Pu, Y. Zhou, and X. Xue, “Two-stage approach for targeted knowledge transfer in self-knowledge distillation,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 11, pp. 2270–2283, Nov. 2024. doi: 10.1109/JAS.2024.124629

|
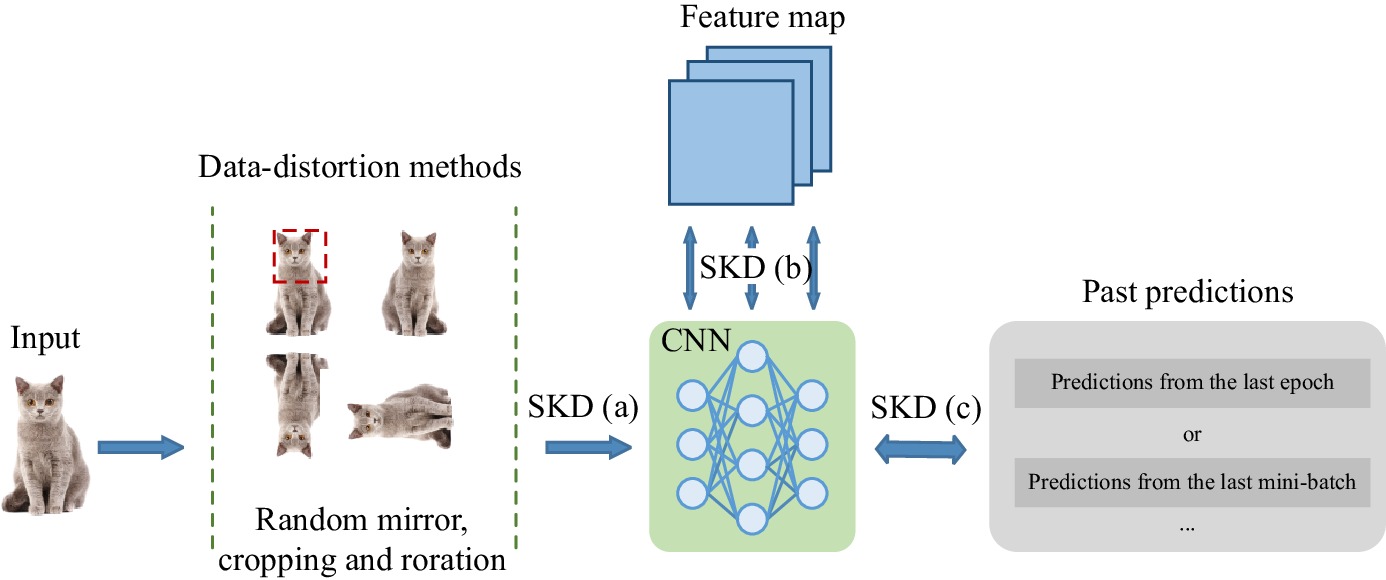
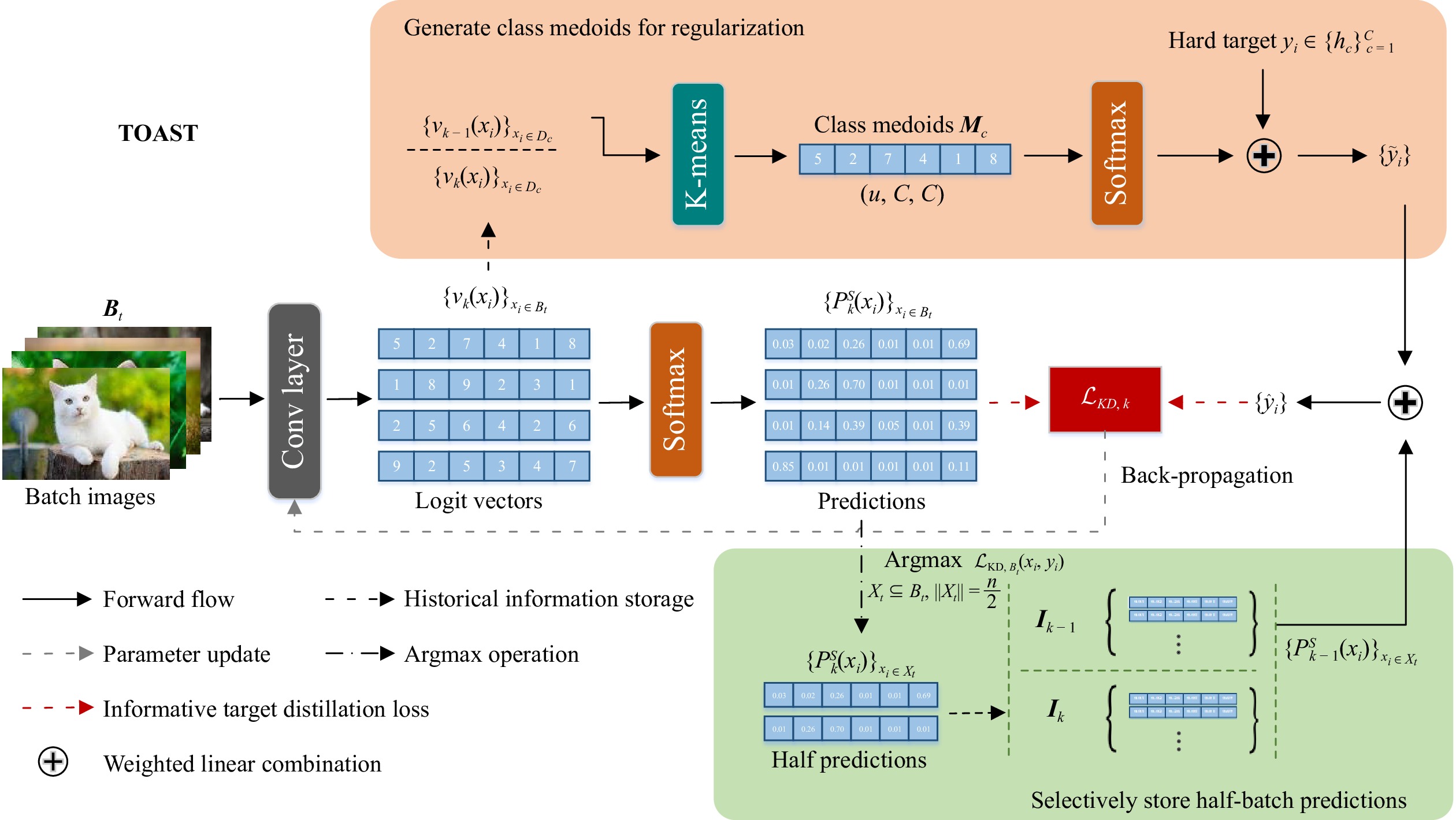
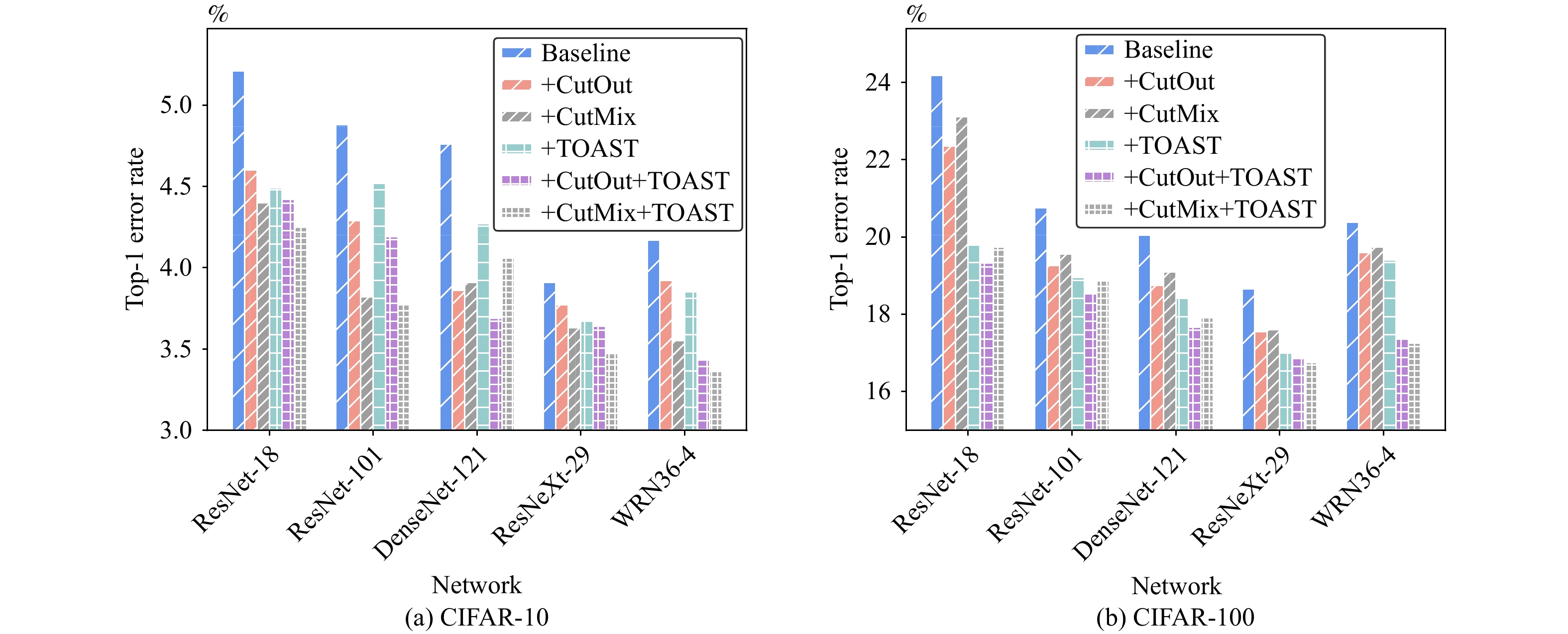
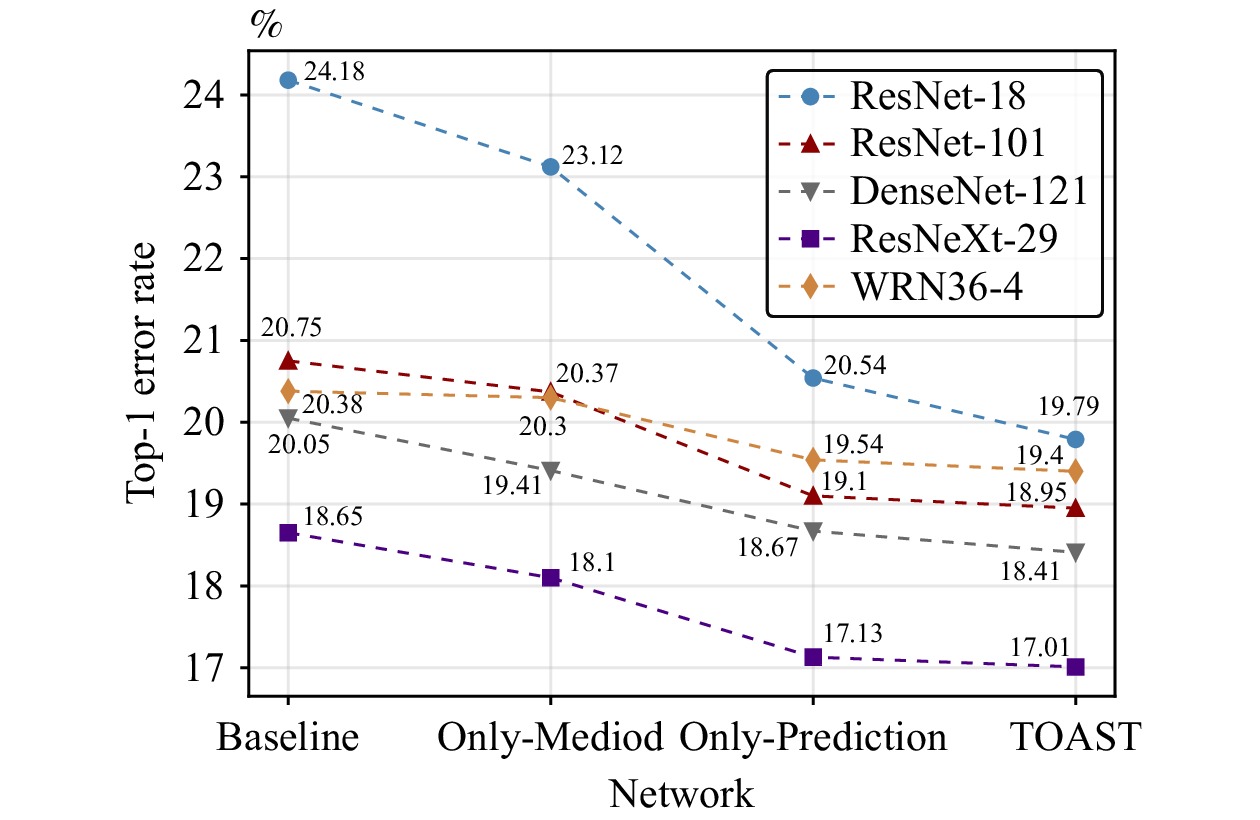
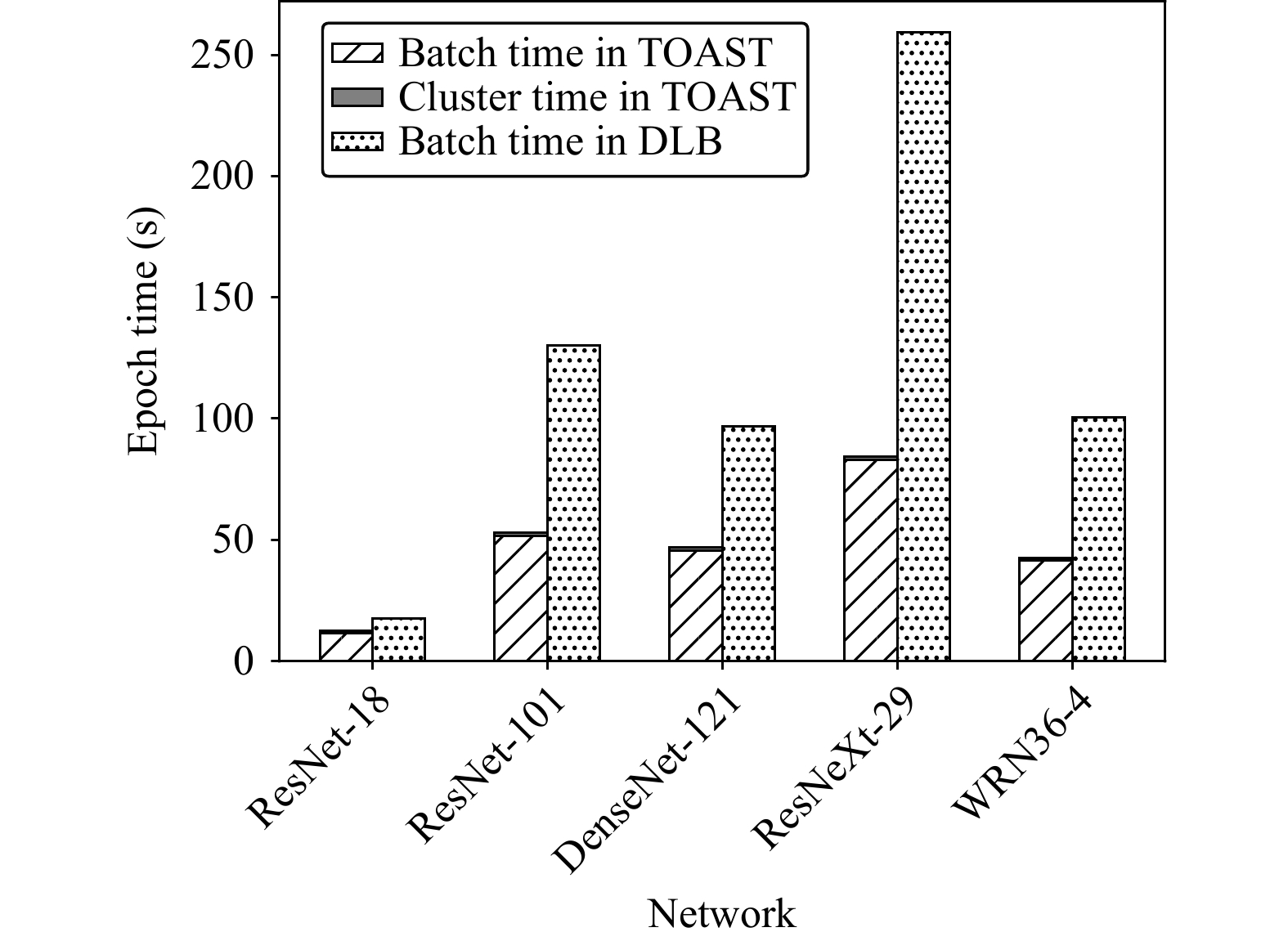
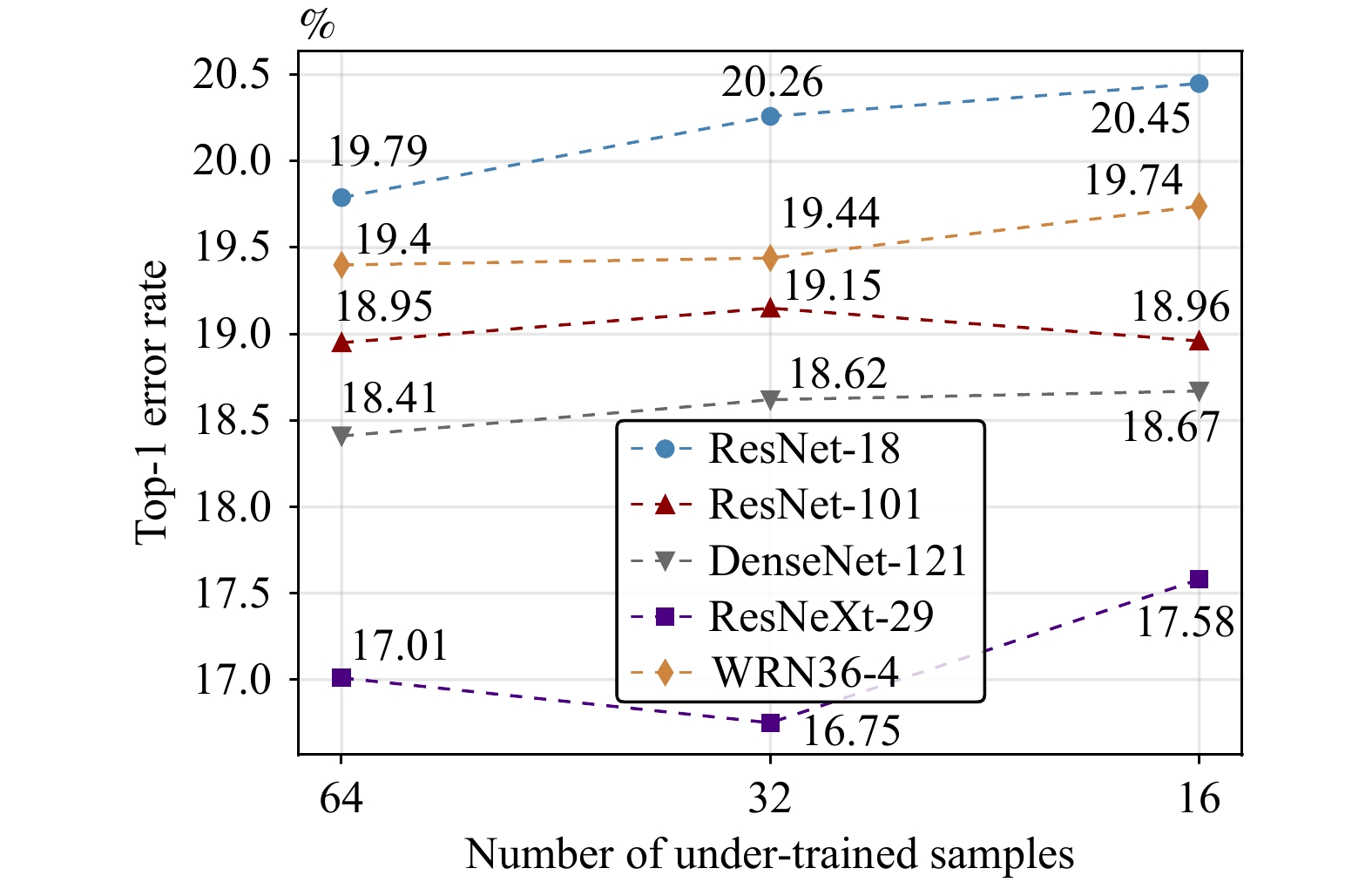
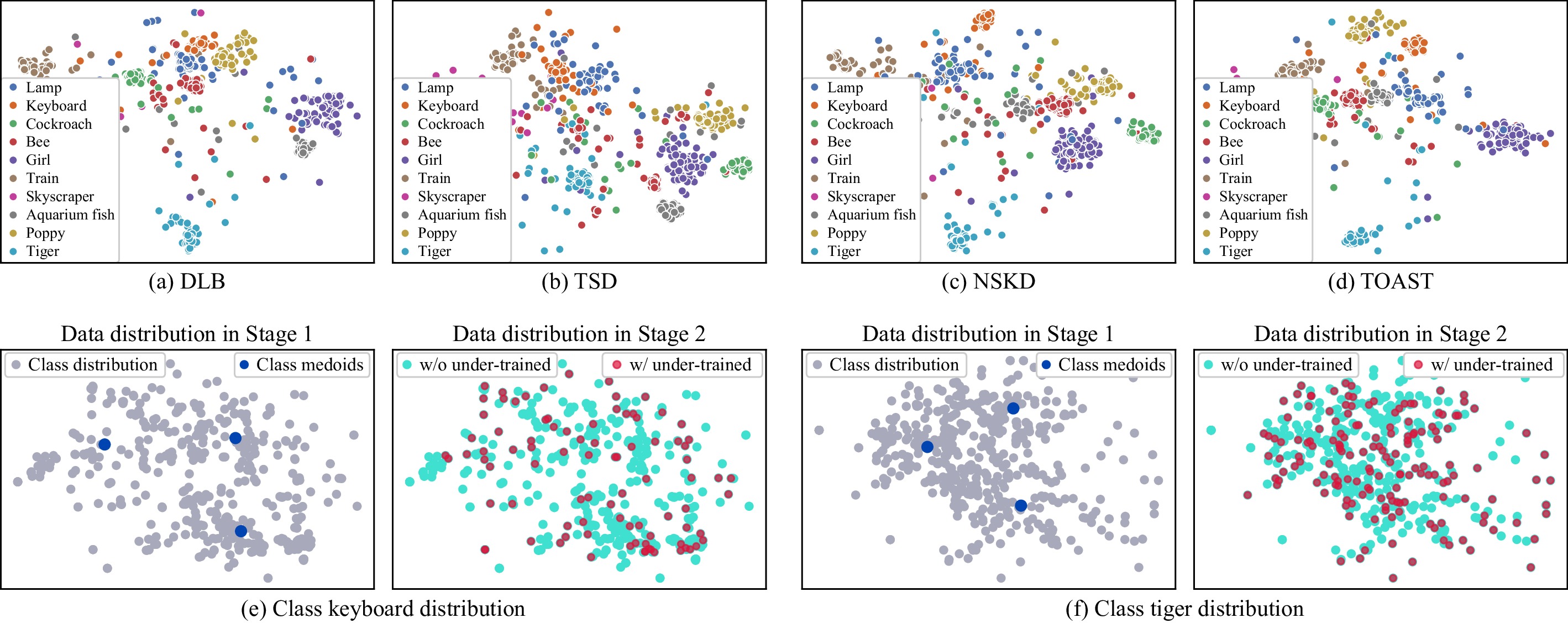
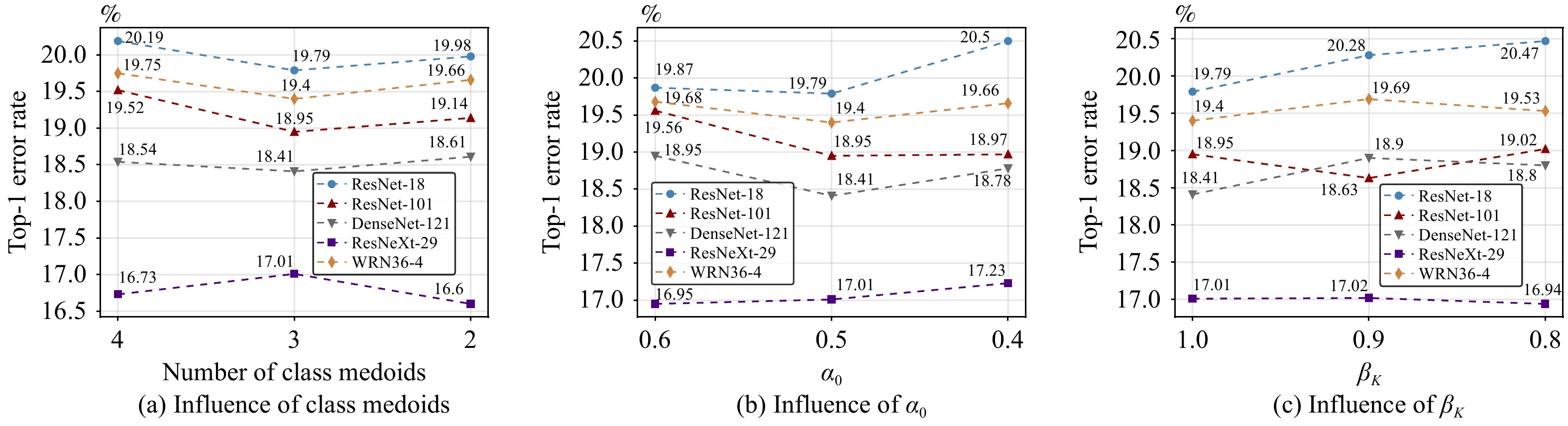
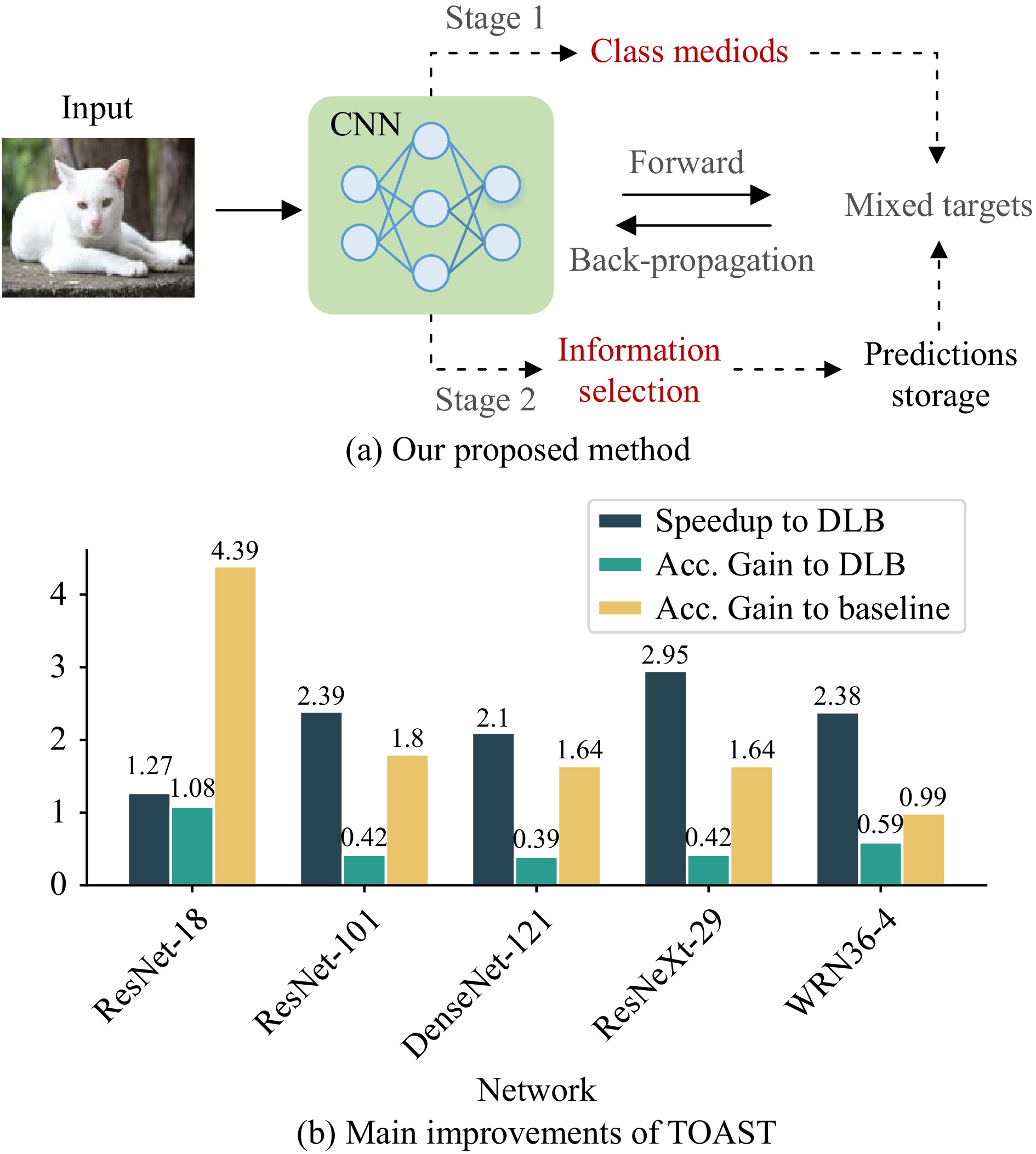
Knowledge distillation (KD) enhances student network generalization by transferring dark knowledge from a complex teacher network. To optimize computational expenditure and memory utilization, self-knowledge distillation (SKD) extracts dark knowledge from the model itself rather than an external teacher network. However, previous SKD methods performed distillation indiscriminately on full datasets, overlooking the analysis of representative samples. In this work, we present a novel two-stage approach to providing targeted knowledge on specific samples, named two-stage approach self-knowledge distillation (TOAST). We first soften the hard targets using class medoids generated based on logit vectors per class. Then, we iteratively distill the under-trained data with past predictions of half the batch size. The two-stage knowledge is linearly combined, efficiently enhancing model performance. Extensive experiments conducted on five backbone architectures show our method is model-agnostic and achieves the best generalization performance. Besides, TOAST is strongly compatible with existing augmentation-based regularization methods. Our method also obtains a speedup of up to 2.95x compared with a recent state-of-the-art method.

| [1] |
P. Chen, S. Liu, H. Zhao, and J. Jia, “Distilling knowledge via knowledge review,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 5008–5017.
|
| [2] |
J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” Int. J. Comput. Vis., vol. 129, pp. 1789–1819, 2021. doi: 10.1007/s11263-021-01453-z
|
| [3] |
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
|
| [4] |
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv: 1412.6550, 2014.
|
| [5] |
N. Komodakis and S. Zagoruyko, “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer,” in Proc. Int. Conf. Learn. Represent., 2017.
|
| [6] |
Y. Shen, L. Xu, Y. Yang, Y. Li, and Y. Guo, “Self-distillation from the last mini-batch for consistency regularization,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 11943–11952.
|
| [7] |
P. Dong, L. Li, and Z. Wei, “DisWOT: Student architecture search for distillation without training,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 11898–11908.
|
| [8] |
Z. Huang, X. Shen, J. Xing, T. Liu, X. Tian, H. Li, B. Deng, J. Huang, and X.-S. Hua, “Revisiting knowledge distillation: An inheritance and exploration framework,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 3579–3588.
|
| [9] |
L. Li, “Self-regulated feature learning via teacher-free feature distillation,” in Proc. Eur. Conf. Comput. Vis. Springer, 2022, pp. 347–363.
|
| [10] |
S. Yun, J. Park, K. Lee, and J. Shin, “Regularizing class-wise predictions via self-knowledge distillation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 13876–13885.
|
| [11] |
C. Yang, Z. An, H. Zhou, L. Cai, X. Zhi, J. Wu, Y. Xu, and Q. Zhang, “MixSKD: Self-knowledge distillation from mixup for image recognition,” in Proc. Eur. Conf. Comput. Vis. Springer, 2022, pp. 534–551.
|
| [12] |
L. Zhang, J. Song, A. Gao, J. Chen, C. Bao, and K. Ma, “Be your own teacher: Improve the performance of convolutional neural networks via self distillation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 3713–3722.
|
| [13] |
K. Kim, B. Ji, D. Yoon, and S. Hwang, “Self-knowledge distillation with progressive refinement of targets,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 6567–6576.
|
| [14] |
C. Buciluǎ, R. Caruana, and A. Niculescu-Mizil, “Model compression,” in Proc. 12th ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., 2006, pp. 535–541.
|
| [15] |
J. Gou, L. Sun, B. Yu, S. Wan, W. Ou, and Z. Yi, “Multilevel attentionbased sample correlations for knowledge distillation,” IEEE Trans. Ind. Informat., vol. 19, no. 5, pp. 7099–7109, 2022.
|
| [16] |
Y. Zhang, T. Xiang, T. M. Hospedales, and H. Lu, “Deep mutual learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4320–4328.
|
| [17] |
J. Kim, M. Hyun, I. Chung, and N. Kwak, “Feature fusion for online mutual knowledge distillation,” in Proc. IEEE 25th Int. Conf. Pattern Recognit., 2021, pp. 4619–4625.
|
| [18] |
J. Gou, L. Sun, B. Yu, L. Du, K. Ramamohanarao, and D. Tao, “Collaborative knowledge distillation via multiknowledge transfer,” IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 5, pp. 6718–6730, 2022.
|
| [19] |
L. Yuan, F. E. Tay, G. Li, T. Wang, and J. Feng, “Revisiting knowledge distillation via label smoothing regularization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 3903–3911.
|
| [20] |
J. Wang, P. Zhang, and Y. Li, “Memory-replay knowledge distillation,” Sensors, vol. 21, no. 8, p. 2792, 2021. doi: 10.3390/s21082792
|
| [21] |
M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Proc. Eur. Conf. Comput. Vis., 2018, pp. 132–149.
|
| [22] |
X. Zhan, J. Xie, Z. Liu, Y.-S. Ong, and C. C. Loy, “Online deep clustering for unsupervised representation learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 6688–6697.
|
| [23] |
R. K. Keser, A. Ayanzadeh, O. A. Aghdam, C. Kilcioglu, B. U. Toreyin, and N. K. Ure, “Pursuhint: In search of informative hint points based on layer clustering for knowledge distillation,” Expert Syst. Appl., vol. 213, p. 119040, 2023. doi: 10.1016/j.eswa.2022.119040
|
| [24] |
J. O’Neill and S. Dutta, “Improved vector quantization for dense retrieval with contrastive distillation,” in Proc. 46th Int. ACM SIGIR Conf. Res. Dev. Inf. Retrieval, 2023, pp. 2072–2076.
|
| [25] |
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 2818–2826.
|
| [26] |
M. Mohri, A. Rostamizadeh, and A. Talwalkar, Foundations of Machine Learning. MIT press, 2018.
|
| [27] |
E. Hoffer, I. Hubara, and D. Soudry, “Train longer, generalize better: Closing the generalization gap in large batch training of neural networks,” in Proc. AAAI Conf. Artif. Intell., vol. 30, 2017.
|
| [28] |
P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He, “Accurate, large minibatch SGD: Training imagenet in 1 hour,” arXiv preprint arXiv: 1706.02677, 2017.
|
| [29] |
Y. Fan, S. Lyu, Y. Ying, and B. Hu, “Learning with average top-k loss,” in Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017.
|
| [30] |
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009.
|
| [31] |
N. Sharma, V. Jain, and A. Mishra, “An analysis of convolutional neural networks for image classification,” Procedia Comput. Sci., vol. 132, pp. 377–384, 2018. doi: 10.1016/j.procs.2018.05.198
|
| [32] |
S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in Proc. IEEE/CVF Int. Conf. Comput. Vis, 2019, pp. 6023–6032.
|
| [33] |
G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” in Proc. Eur. Conf. Comput. Vis. Springer, 2020, pp. 588–604.
|
| [34] |
C.-B. Zhang, P.-T. Jiang, Q. Hou, Y. Wei, Q. Han, Z. Li, and M.-M. Cheng, “Delving deep into label smoothing,” IEEE Trans. Image Process., vol. 30, pp. 5984–5996, 2021. doi: 10.1109/TIP.2021.3089942
|
| [35] |
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778.
|
| [36] |
S. Zagoruyko and N. Komodakis, “Wide residual networks,” arXiv preprint arXiv: 1605.07146, 2016.
|
| [37] |
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 4700–4708.
|
| [38] |
S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 1492–1500.
|
| [39] |
M. Liu, Y. Yu, Z. Ji, J. Han, and Z. Zhang, “Tolerant self-distillation for image classification,” Neural Netw., p. 106215, 2024.
|
| [40] |
P. Liang, W. Zhang, J. Wang, and Y. Guo, “Neighbor self-knowledge distillation,” Inf. Sci., vol. 654, p. 119859, 2024. doi: 10.1016/j.ins.2023.119859
|
| [41] |
M. P. Naeini, G. Cooper, and M. Hauskrecht, “Obtaining well calibrated probabilities using bayesian binning,” in Proc. AAAI Conf. Artif. Intell., 2015.
|
| [42] |
Y. Geifman, G. Uziel, and R. El-Yaniv, “Bias-reduced uncertainty estimation for deep neural classifiers,” arXiv preprint arXiv: 1805.08206, 2018.
|
| [43] |
T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv: 1708.04552, 2017.
|
| [44] |
S. Irandoust, T. Durand, Y. Rakhmangulova, W. Zi, and H. Hajimirsadeghi, “Training a vision transformer from scratch in less than 24 hours with 1 GPU,” in Has It Trained Yet? NeurIPS 2022 Workshop, 2022. [Online]. Available: https://openreview.net/forum?id=sG0I6AIvq3
|
| [45] |
C. Yang, H. Zhou, Z. An, X. Jiang, Y. Xu, and Q. Zhang, “Cross-image relational knowledge distillation for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 12319–12328.
|
| [46] |
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE,” J. Mach. Learn. Res., vol. 9, no. 11, 2008.
|
| [47] |
J. Xie, W. Kong, S. Xia, G. Wang, and X. Gao, “An efficient spectral clustering algorithm based on granular-ball,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 9, pp. 9743–9753, 2023.
|
| [48] |
R. Zhang, H. Peng, Y. Dou, J. Wu, Q. Sun, Y. Li, J. Zhang, and P. S. Yu, “Automating dbscan via deep reinforcement learning,” in Proc. 31st ACM Int. Conf. Inf. Knowl. Manag., 2022, pp. 2620–2630.
|
| [49] |
L. Manduchi, M. Vandenhirtz, A. Ryser, and J. Vogt, “Tree variational autoencoders,” in Proc. Adv. Neural Inf. Process. Syst., vol. 36, 2023, pp. 54952–54986.
|
Figures(9) / Tables(8)






 DownLoad:
DownLoad: